I joined the ml.school community back in May of 2023 to further my MLOps knowledge and skills. The school/community is founded by Santiago Valdarrama. Like many on the course I discovered Santiago through his engaging ML content on YouTube/Twitter.
Deploying/operating Machine Learning models share similarities with Fullstack applications. Just as Fullstack applications demand APIs for interfacing with other software, CI/CD pipelines for automating QA and deployment, as well as database deployment, application monitoring, machine learning models require these elements.
Where practices diverge, becomes evident in the area(s) of operating data pipelines, model monitoring and the strategies used to sustain model performance. It is important to acknowledge that MLOps is quite nascent and so practices are rapidly evolving.
Course syllabus
Every two weeks there is a new cohort, each cohort is composed of six modules: a lecture is given for each one — on Mondays, Wednesdays and Fridays. In the earlier cohorts — Santiago would focus on code walkthroughs but he has, in my opinion, improved the structure of lectures and used them to impart the principles/goals of MLOps and invites the audience to think about the underlying motivations of current practices from first principles.
Furthermore, an “Office Hours” is given every two weeks where members of the community can get together on a call and discuss all things ML/MLOps or whatever your shared interest is. This has been one of the most valuable parts of the course — to date there has been seven cohorts — I joined the community with cohort two.
Currently, all members are given lifetime membership. Providing you with unlimited access to resources, updated content and community forums. I have continued to keep abreast of the course material and occasionally attend cohorts/“Office Hours”. Santiago is consistently improving the material, based on new findings and feedback from the community.
The course is centred around two datasets — MNIST and Penguins.
Assignments focus on making changes to the existing SageMaker pipeline that utilises the Penguins dataset, whilst taking those learnings and applying those to your own pipeline using the MNIST dataset.
Code to the sessions can be found here.
The six modules are as follows, each module has a set of assignments primarily to do with code modifications. Since Cohort 2 these have been enriched by the inclusion of theoretical questions:
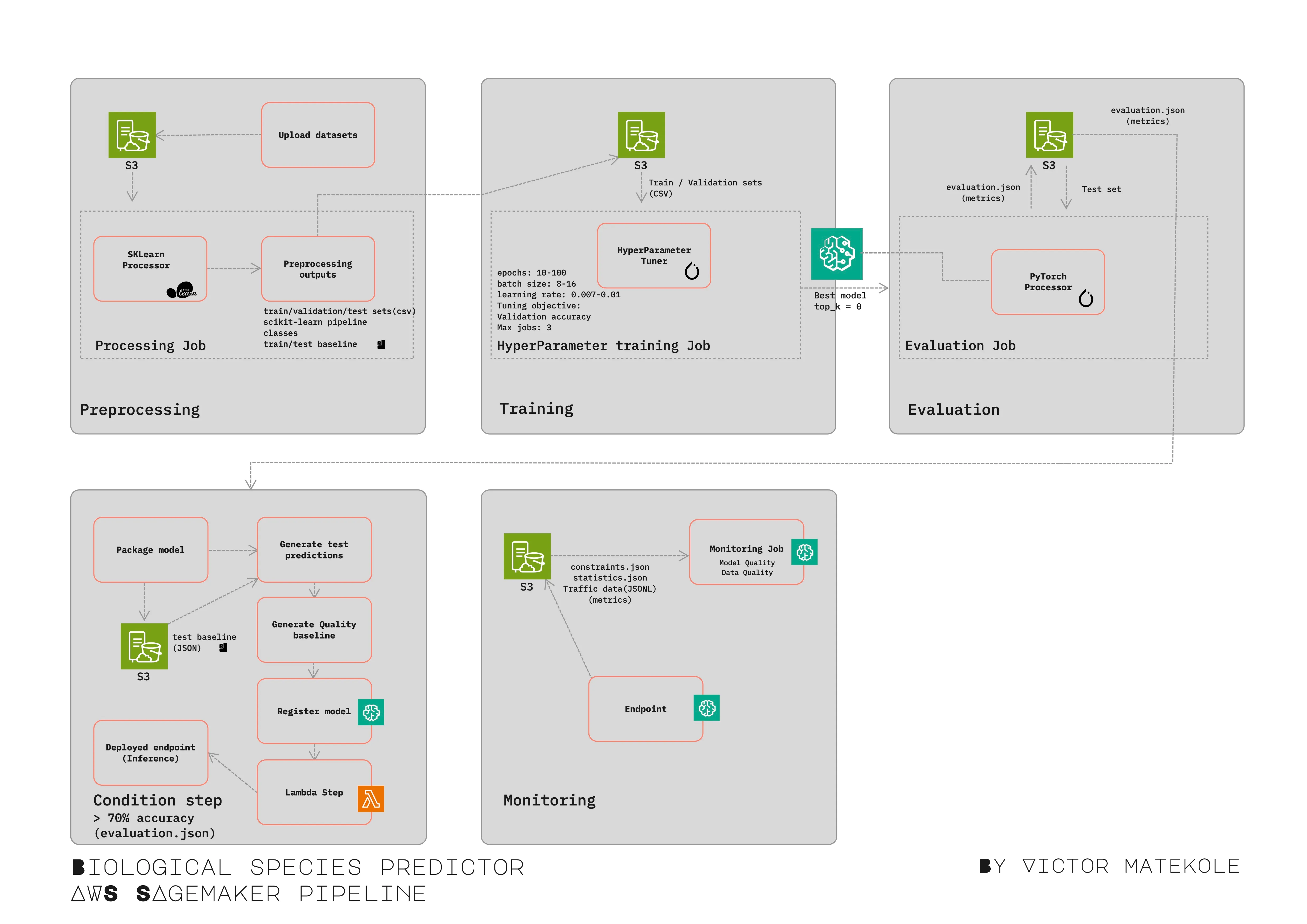
Session 1 — Preprocessing
A scikit-learn pipeline is implemented to preprocess the data and generate data baselines for real-time monitoring of the model. The same pipeline will eventually be used for Inference. S3 is used for persisting outputs.
The following outputs are the basis for creating dependencies between further steps in the pipeline:
-
Feature Engineering
-
Training/Test/Validation splits
-
Baseline data/statistics generation (for model monitoring)
Session 2 — Training / Tuning
In this session we discuss model training and its practices. In particular, SageMaker hyperparameter training and subsequent impact of the various parameter(s) on training performance and costs. A training script is passed to a Tuner. A maximum of 3 jobs are created, each producing a model. Eventually the best performing model is chosen for subsequent evaluation.
Session 3 — Model Evaluation
Next up is model evaluation where the “test” dataset is used to assess the best performing model from the hyperparameter training step. Based on pre-defined benchmarks, models will be rejected or approved in the next step.
Session 4 — Model Registration
Model registration is an important step in experiment tracking as it is where our most important outputs from training and evaluations are stored, the models! Models are registered along with their performance metrics/model cards and can be assigned various statuses such as “Approved” / “PendingApproval”.
Session 5 — Model Deployment
Unlike the previous steps in the pipeline e.g. TuningStep or ProcessingStep; SageMaker doesn’t offer a step targeted at deployment. Instead, a LambdaStep is used to deploy the endpoint and its configuration. Lambda is AWS’s serverless functions offering and allows the execution of arbitrary code without the need to manage a server. Its configuration will allow you to define in percentage terms how much data should be captured for monitoring.
From what I understand from the lecture — AWS will handle the deployment without interrupting traffic i.e. downtime.
Session 6 — Model Monitoring
The final module goes into real-time monitoring of the model. The lecture dives into a number of practices that are commonly used to assess model performance. These practices are targeted at both business and technical KPIs. In the case of the code implementation — the focus is on technical performance by assessing data drift, by comparing production data with the statistics generated in the earlier preprocessing step. Furthermore, the drivers for what data splits(train, validation or test) should be used for detecting model drift and more importantly why!. Finally, we go into strategies to keep models resilient, despite shifts in data distributions.
Important note: You will have to request to AWS Service Quotas to increase TransformJob quota for ml.m5.large!
Projects / Assignments
One of the most informative assignments I carried out was the re-implementation of the Neural Network from TensorFlow to PyTorch. From my experience, SageMaker does not abstract away from the developer the differences between these frameworks. In particular when implementing the inference script, it felt the frameworks diverged considerably and that the APIs were developed by two different teams, who had little alignment or goals in developing a unified interface between Pytorch/TensorFlow models.
Since my cohort(#2) — assignments have undergone significant transformation, encouraging students to think about underlying principles and motivations for why a practice exists. Santiago’s teaching approach consistently emphasises this aspect, as he aims to foster a deep understanding rooted in first principles. This approach is both refreshing and encourages you to convincingly internalise the subject matter.
SageMaker
I generally found the developer experience of SageMaker sub-optimal and in some cases frustrating… The framework is buggy(bugs would often be found during and after implementation), restrictive, counter-expressive and slow. There is far too much boilerplate to get simple things done. Applying logic within the pipeline does not allow for freedom of expression and restricts the developer to a rigid, over regimented framework to implement simple logic. It’s possible that I’m overlooking SageMaker’s objectives, and maybe its approach aligns better with tackling large-scale issues. However, I’m struggling to identify a clear rationale or justification for some of its design decisions.
There unfortunately isn’t much I can put in the plus box; Other than SageMaker attempts to provide a unified solution for MLOps, where alternatives require a suite of integrated tools.
In comparison to my experience of alternative MLOps implementations:
- MLFlow(Experiment tracking/Model registration)
- Optuna(Hyper parameter training)
- FastAPI(Inference)
- Evidently/Prometheus/Grafana(Model monitoring).
Despite the solution leveraging, a heterogeneous set of tools, which is a typical Unix-style approach. The developer experience was vastly more productive and enjoyable.
In SageMaker’s defence I was to later find solutions such as “local pipelines” which would have reduced code/testing cycles as pipelines are slow to run even on small datasets. However, it appears that the industry is discovering practices where integrating open source tools like MLFlow with SageMaker would lead to increased productivity. In fact, based on recent feedback from the community, MLFlow will be included in subsequent updates of the course material.
To conclude, I would only recommend SageMaker if my company/organisation was already invested in AWS or at best, use it for compute.
How to get the best from the course
Do the assignments, especially the ones you find hard, the easy ones you can skip! Attend every session at least once and a couple of the “Office Hours”. It is these sessions that were most valuable to me. I expect as long as I remain in ML, I will always contribute to this community and will continue to learn as it grows.
Conclusion
Santiago is energetic, enthusiastic, tentative, open and wants to take you deep into a journey of MLOps. Most importantly he wants you to internalise why a practice exists and invites you to think and perhaps challenge its premise. It is the community and his support that is most valuable. I look forward to seeing ml.school evolve and grow. I highly recommend it.